
[Java/Kotlin] 빅 엔디안(Big-Endian)과 리틀 엔디안(Little-Endian) 변환 예제
빅 엔디안과 리틀 엔디안의 개념에 대한 설명은 다른 글에서 정리해 두었다.
구글링해서 예제를 찾아보니 구현은 보통 C언어로 된 게 많은 것 같다. 나는 C언어보다 Java가 편해서 Java와 Kotlin으로 한번씩 짜봤다. 예제를 만들면서 새로이 알게 된 사실도 같이 정리하려고 한다. 이 글에서 비트연산자에 대한 설명은 따로 하지 않을 것이다.
네트워크로 데이터를 전송할 때 같은 엔디안 시스템을 사용하는 컴퓨터에서는 호환성 문제가 생기지 않는다. 하지만 서로 다른 엔디안을 사용하는 컴퓨터의 경우 컴퓨터가 데이터를 제대로 읽지 못하는 경우가 생길 수 있다. 때문에 바이트의 정렬 방법을 변환해야 하는 경우가 있다.
변환 방식을 설명하기 위해 0x12345678를 예로 들어보겠다.
이 16진수를 32비트의 이진수로 바꾸면 0001 0010 0011 0100 0101 0110 0111 1000이 된다.
4바이트의 배열로 표현해보자.
| byte[0] | byte[1] | byte[2] | byte[3] |
| 0001 0010 | 0011 0100 | 0101 0110 | 0111 1000 |
1) little endian 변환
목표는 바이트가 저장되는 순서를 역순으로 바꾸는 것이다. 좌에서 우로 1바이트씩 값을 밀어내도록 shift 연산을 해보자.
- 아무것도 하지 않았을 때 : 0001 0010 0011 0100 0101 0110 0111 1000
- 1바이트만큼 shift right 했을 때 : 0000 0000 0001 0010 0011 0100 0101 0110
- 2바이트만큼 shift right 했을 때 : 0000 0000 0000 0000 0001 0010 0011 0100
- 3바이트만큼 shift right 했을 때 : 0000 0000 0000 0000 0000 0000 0001 0010
빨간색으로 강조한 가장 끝자리 1바이트의 값이 차례대로 78, 56, 34, 12가 되었다. 이제 이걸 떼어서 배열에 담아주기만 하면 된다. 매개변수로 주어진 변수 value로 shift 연산을 하고, byte로 형변환을 하면 1byte를 초과하는 24비트가 날아가고 우리에게 필요한 하단의 8비트만 남게된다.
Java
byte[] convertToLittleEndian(int value) {
return new byte[]{
(byte) value,
(byte) (value >> 8),
(byte) (value >> 16),
(byte) (value >> 24)
};
}
Kotlin
fun convertToLittleEndian(value: Int): ByteArray = byteArrayOf(
value.toByte() and 0xFF,
(value shr 8).toByte(),
(value shr 16).toByte(),
(value shr 24).toByte()
)
함수를 실행해보면 이런 배열이 반환될 것이다.
| byte[0] | byte[1] | byte[2] | byte[3] |
| 0111 1000 | 0101 0110 | 0011 0100 | 0001 0010 |
2) big endian 변환
원리는 little endian 변환과 동일하다. 배열에 넣는 순서만 반대로 하면 된다.
Java
byte[] convertToBigEndian(int value) {
return new byte[]{
(byte) (value >> 24),
(byte) (value >> 16),
(byte) (value >> 8),
(byte) value
};
}
Kotlin
fun convertToBigEndian(value: Int): ByteArray = byteArrayOf(
(value shr 24).toByte(),
(value shr 16).toByte(),
(value shr 8).toByte(),
value.toByte()
)함수를 실행해보면 이런 배열이 반환될 것이다.
| byte[0] | byte[1] | byte[2] | byte[3] |
| 0001 0010 | 0011 0100 | 0101 0110 | 0111 1000 |
3) Byte array를 Int로 변환하기
이제 byte array를 출력해보기 위해 다시 int형으로 변환한다.
Java
int bytesToInt(byte[] bytes) {
int result = (int) bytes[3] & 0xFF;
result |= (int) bytes[2] << 8 & 0xFF00;
result |= (int) bytes[1] << 16 & 0xFF0000;
result |= (int) bytes[0] << 24;
return result;
}
Kotlin
fun bytesToInt(byteArray: ByteArray): Int {
var result = byteArray[3].toInt() and 0xFF
result = result or (byteArray[2].toInt() shl 8 and 0xFF00)
result = result or (byteArray[1].toInt() shl 16 and 0xFF0000)
result = result or (byteArray[0].toInt() shl 24)
return result
}
0x12345678이 인수로 들어온 경우를 보자.
초기화되지 않은 result 변수는 최초에 0000 0000 0000 0000 0000 0000 0000 0000를 가지고 있을 것이다.
- byteArray[3].toInt() : 0000 0000 0000 0000 0000 0000 0111 1000
- byteArray[2].toInt() shl 8 : 0000 0000 0000 0000 0101 0110 0000 0000
- byteArray[1].toInt() shl 16 : 0000 0000 0011 0100 0000 0000 0000 0000
- byteArray[0].toInt() shl 24 : 0001 0010 0000 0000 0000 0000 0000 0000
이렇게 변환한 값과 result 변수로 or 연산을 적용한다.
or은 두 값 중 하나 이상 1이 있으면 1을 반환한다. 예를들어 0000 or 0011은 0011이 된다. or 연산은 byteArray의 값이 result 변수에 차례대로 반영되는 효과를 낸다. 함수를 실행하면 0001 0010 0011 0100 0101 0110 0111 1000, 16진수로는 12345678이 반환될 것이다.
and 0xFF는 왜 쓴걸까?
or 연산을 정상적으로 수행하기 위해 필요하다. 근본적인 이유는 Java가 unsigned를 지원하지 않기 때문이다.
함수에서 and 0xFF, and 0xFF00, and 0xFF0000를 지우고 0x12345680이나 0x12830612를 인수로 집어넣고 실행해보자.
각각 ffffff80과 ff830612가 출력된다. 갑자기 멀쩡한 숫자가 ff로 바껴서 나왔다. 이게 대체 무슨 일인가 싶다.
int형 변환을 할 byte 값이 0x80이라 가정하자. 0x80을 비트로 표현하면 1000 0000이다.
단위가 작은 자료형이 더 큰 단위의 자료형으로 바뀔 때는 부호비트에 따라 빈 자리가 채워진다.(부호 확장) Java는 unsigned int를 지원하지 않기 때문에 최상위 비트인 1을 보고 값을 음수로 이해해 상위에 있는 24자리를 모두 1로 채우게 된다. 0x80이 int로 변환된 순간 값은 1111 1111 1111 1111 1111 1111 1000 0000이 되며 or 연산을 적용한 순간 1로 채워진 0~2번째 자리의 바이트들은 무조건 0xFF가 되어버린다.
8 이상의 숫자로 시작하는 바이트가 있다면 이진수로 변환했을 때 무조건 최상위 비트가 1이된다. 때문에 해당 바이트의 앞자리에 대해선 항상 동일한 문제가 발생할 것이다.
따라서 or 연산이 필요한 바이트 외의 자리를 모두 0으로 만들어야 정상적인 결과를 얻을 수 있다.
0xFF(이진수로는 0000 0000 0000 0000 0000 0000 1111 1111)과 and 연산을 하면 앞쪽 세개의 바이트는 모두 0으로 채워진다.
그 외에 알게된 사실
Kotlin 코드에서 함수를 호출할 때 0x80123456이나 0x90000000처럼 8이상의 숫자로 시작하는 8자리 값을 넣으면 Java에선 없던 syntax error가 생긴다.

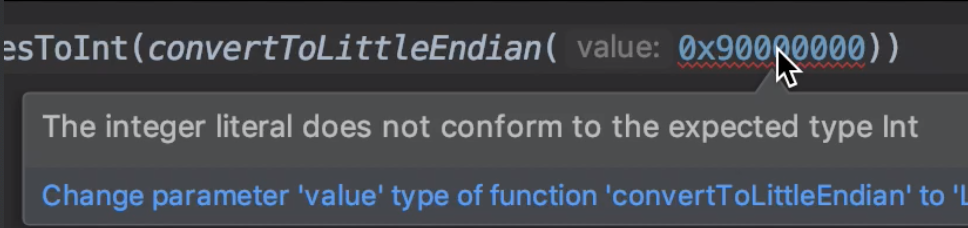
Java와 달리 Kotlin은 자동 형변환이 안돼서 그렇다.
int 타입은 32비트의 사이즈를 가지는 자료형이라 2^32 만큼의 숫자를 표현할 수 있을 것 처럼 생각된다. 하지만 Integer.toHexString(Integer.MAX_VALUE)를 실행해보자. ffffffff가 아니라 7fffffff이 출력된다. 실질적인 값을 표현하는 것은 31비트이고, 최상위 1비트는 부호 비트로 사용되기 때문이다.
따라서 8 이상의 수로 시작하는 16진수는 컴파일러가 out of range로 인식한다.
Kotlin에서 이 오류를 없애려면 1) convertToLittleEndian()의 매개변수 타입을 Long으로 바꾸던가 2) 인수의 값을 0x90000000.toInt()로 형변환 해줘야 한다.
val test1: Int = 0x80000000 // error
val test2: Int = 0x80000000.toInt() // works디컴파일을 해봤더니 test2는 Integer.toBinaryString((int)2147483648L)가 되더라.
내부적으로 0x80000000를 0x80000000L로 변경한 후 int 형변환을 하나보다.
생각해보면 당연한 일이지만 int형 변수로 21억 이상의 숫자를 쓸일이 없었기에 처음 알게된 사실이다.
이 문제에 대한 자세한 내용은 링크에서도 확인할 수 있다.
전체 소스코드
Java
public class EndianConverter {
public static void main(String[] args) {
EndianConverter endianSystem = new EndianConverter();
int test1 = endianSystem.bytesToInt(endianSystem.convertToLittleEndian(0x12345678));
int test2 = endianSystem.bytesToInt(endianSystem.convertToBigEndian(0x12345678));
System.out.println(Integer.toHexString(test1)); // 실행결과 78563412이 출력됨
System.out.println(Integer.toHexString(test2)); // 실행결과 12345678이 출력됨
}
byte[] convertToLittleEndian(int value) {
return new byte[]{
(byte) value,
(byte) (value >> 8),
(byte) (value >> 16),
(byte) (value >> 24)
};
}
byte[] convertToBigEndian(int value) {
return new byte[]{
(byte) (value >> 24),
(byte) (value >> 16),
(byte) (value >> 8),
(byte) value
};
}
String byteToStr(byte[] bytes) {
StringBuilder builder = new StringBuilder();
for (byte b : bytes) {
builder.append(String.format("%02x ", b));
}
return builder.toString();
}
int bytesToInt(byte[] bytes) {
int result = (int) bytes[3] & 0xFF;
result |= (int) bytes[2] << 8 & 0xFF00;
result |= (int) bytes[1] << 16 & 0xFF0000;
result |= (int) bytes[0] << 24;
return result;
}
}
Kotlin
class EndianConverter {
fun convertToLittleEndian(value: Int): ByteArray = byteArrayOf(
value.toByte(),
(value shr 8).toByte(),
(value shr 16).toByte(),
(value shr 24).toByte()
)
fun convertToBigEndian(value: Int): ByteArray = byteArrayOf(
(value shr 24).toByte(),
(value shr 16).toByte(),
(value shr 8).toByte(),
value.toByte()
)
fun bytesToStr(byteArray: ByteArray): String {
val builder = StringBuilder()
for (b in byteArray) {
builder.append(String.format("%02x ", b))
}
return builder.toString()
}
fun bytesToInt(byteArray: ByteArray): Int {
var result = byteArray[3].toInt() and 0xFF
result = result or (byteArray[2].toInt() shl 8 and 0xFF00)
result = result or (byteArray[1].toInt() shl 16 and 0xFF0000)
result = result or (byteArray[0].toInt() shl 24)
return result
}
}'if (study) > 기본기 수련' 카테고리의 다른 글
| 아키텍처 별 특징과 폰노이만 병목에 발생하는 트래픽 정리 (0) | 2019.10.21 |
|---|---|
| 메모리의 속성과 빅 엔디안(Big-Endian), 리틀 엔디안(Little-Endian) 정리 (1) | 2019.10.16 |
| 주소 지정 방식(Memory Addressing Modes) 정리 (0) | 2019.09.17 |