
코틀린을 다루는 기술 5장 정리 - 리스트로 데이터 처리하기
코틀린을 다루는 기술 5장을 읽고 정리한 내용입니다.
요약된 표현이 많기에 보다 자세한 설명은 책을 통해 확인하실 수 있습니다.
데이터 구조는 특정한 타입의 객체가 여럿 모인 것을 가리키며, 이런 모임 전체를 컬렉션(collection)이라고 부른다. List를 비롯하여 코틀린에서 제공하는 immutable list는 사실 immutable하지 않다. 물론 List 인터페이스는 읽기 전용 자료구조로 데이터를 변경할수 있는 메서드를 제공하지 않지만, List를 MutableList로 캐스팅하는 방법을 사용하면 데이터는 프로그램 실행 도중에 변경될 가능성이 있다.
fun main(args: Array<String>) {
val list: List<String> = listOf("This", "Is", "Totally", "Immutable")
(list as MutableList<String>)[2] = "Not"
println(list.joinToString()) // 실행 결과 This, Is, Not, Immutable가 출력된다
}이번 장에서는 데이터 공유를 사용해 원소 추가, 삭제 연산이 보디 효율적이고, 찐 불변 리스트인 Singly linked list를 구현해본다.
5.1 데이터 컬렉션을 분류하는 방법
- 선형(linear) 컬렉션 : 원소들이 일차원으로 관계된 컬렉션이다.
List처럼 각 원소가 다음 연소와 연관되어 있다. - 연관(associative) 컬렉션 : 함수와 비슷한 유형의 컬렉션이다.
Map처럼 원소 사이에는 아무런 관계가 없고, 특정한 객체 O와 O에 대응하는 값 V로 이뤄진 연관 관계의 집합이다. - 그래프(graph) 컬렉션 : 각 원소가 여러 개의 다른 원소와 연관되어 있는 컬렉션이다. 대표적으로
Tree가 있다.
5장에서는 선형 컬렉션이 주인공이고, 연관 컬렉션과 그래프 컬렉션은 각각 11장, 10장에서 다룰 예정이다.
5.2 리스트의 여러 유형
리스트를 세부적으로 구분할 수 있는 여러 가지 접근법을 알아보자.
- 접근 유형 : 한쪽 끝에서만 접근, 양 끝에서 모두 접근, index를 활용해 원하는 요소에 바로 접근
- 접근 순서 : FIFO(선입 선출), LIFO(후입 선출) 등
- 구현 : 원소가 다음 원소와 연결된 구현 방식, 인덱스로 접근 가능한 구현 방식 등, 접근 유형과 접근 순서는 리스트의 구현 방식과 밀접하게 연관된다.
5.3 리스트의 상대적 예상 성능
시간 복잡도와 공간 복잡도 맞바꾸기
모든 유형의 연산에 대해 O(1) 성능을 제공한다면 베스트겠지만, 아쉽게도 그런 자료구조는 현재로썬 존재하지 않는다. 데이터 구조를 선택하는 기준은 일반적으로 시간과 공간 복잡도를 맞바꾸는 것이다. 가장 자주 써야 하는 연산이나, 필요한 정렬 순서 등을 기준으로 성능이 가장 우수한 자료 구조를 선택하는 것이 중요하다.
제자리 상태 변이 피하기
데이터 구조는 원소를 삽입, 삭제 연산 시 변화한다. 이런 연산을 처리하는 데는 크게 두 가지 방식이 존재한다.
- 제자리 갱신 (update in place)
- 데이터 구조의 상태를 변이해 데이터 구조를 이루는 원소를 바꾸는 방식이다. 간단하게 말해서, 원본 데이터를 직접 변경하는 가변 데이터 구조이다.
- 다중 쓰레드 기반의 프로그램이라면, 데이터 구조를 변이 하는 모든 연산에서 thread-safe를 보장하기 위한 각종 처리가 필요하다는 문제가 생긴다.
- 불변 데이터 구조 사용
- 제자리 갱신의 동시성 문제를 해결하기 위해 불변 데이터 구조를 사용한다. 이런 이미 존재하는 내용을 변경하는 대신 새로운 상태를 표현하는 데이터를 새로 만든다. (ex. Java의 String)
- 이 경우 원소가 변경될 때 다른 스레드가 같은 리스트를 처리하고 있어도 그 쓰레드에는 리스트 변경이 보이지 않기 때문에 아무런 영향이 없다.
불변 데이터 구조에서 생길 수 있는 문제점
-
다른 스레드가 데이터 변경을 알 수 없다면 그 스레드는 잘못된 데이터를 조작하게 된다.
→ 스레드가 낡은 데이터를 조작한다는 말은, 쓰레드가 읽기 시작한 순간에 존재하던 데이터 상태를 읽는다는 말이다. 따라서 쓰레드가 데이터를 조작한 후 다른 스레드에서 삽입이 일어난다면 동시성에 문제가 없다.
-
데이터에 변경이 생길 때마다 새 리스트를 만들 때 생기는 오버헤드
→ 코틀린의 불변 리스트가 이 경우에 해당한다. 리스트에 단 하나의 요소를 추가하는데도 O(n)의 시간이 걸리는 데다, 메모리도 중복으로 낭비되는 문제가 있다. 데이터를 공유하는 특별한 데이터 구조를 구현하는 방식으로 이 문제를 해결할 수 있다.
5.4 코틀린에서 사용할 수 있는 리스트의 종류
코틀린은 불변 리스트와 가변 리스트를 제공한다. 둘 다 자바의 List를 기반으로 만들어져 있다.
-
가변 리스트
- 자바 리스트와 똑같이 작동한다. 원소 추가, 제거, 삽입을 통해 리스트를 변이 시킬 수 있다. 위에서 언급한 제자리 갱신 방식을 사용해 리스트의 데이터를 직접 변경한다.
-
불변 리스트
참조하는 포인터가 같다면, 그 값은 (나중에라도) 반드시 같다.
- 직접적인 연산으로 변경이 불가능하다. 원소 추가, 삽입, 삭제가 발생하면 원래 리스트의 복사본을 만든다.
- 장점은 해당 레퍼런스(포인터)를 가진 어떤 주체도 그 값이 영원히 바뀔 걱정 없이, 마음 놓고 믿고 쓸 수 있다는 뜻이다. 바뀌지 않으니 참조하는 순서(order)나 시점(time)을 고려할 필요가 없고, thread-safety 문제도 고민할 필요가 없다.
- 자바 리스트는 영속화(persistency)를 제공하지 않아서(=메모리 주소가 변경되면서 이전 데이터를 찾을 수 없음) 방어적 복사 기법(defensive copy)을 통해 데이터를 영속화한다. 방어적 복사는 다른 스레드로부터 데이터 변이가 발생하는 일을 방지하기 위해 복사본을 만드는 것을 의미한다.
영속적인 데이터 구조(Pesistent Data Structures) 사용하기
다음은 위키백과에 나와있는 영속적인 데이터 구조의 정의다.
In computing, a persistent data structure is a data structure that always preserves the previous version of itself when it is modified
영속적인 데이터 구조는 데이터에 변경이 생기더라도, 이전 버전이 언제나 유지되는 자료 구조다. 데이터 구조에 원소를 추가하기 전 복사본을 만들면서 생기는 오버헤드를 방지하기 위해 데이터 공유(data sharing)라는 기법을 사용한다. 데이터 공유는 불변이면서 영속적인 데이터 구조의 토대가 되는 기법이다.
원래 버전의 자료 구조를 유지한 채 약간 변형된 새 버전을 만듦으로써 기존의 데이터를 공유하고, 이렇게 구현된 리스트는 변이를 사용하는 리스트보다 훨씬 효율적으로 원소를 삭제하고 삽입할 수 있다.
불변이며 영속적인 단일 연결 리스트(Singly linked list)
단일 연결 리스트는 가장 단순한 형태의 영속적인 데이터 구조다. 한번 노드가 할당되고 나면 오로지 복사만 가능하며, 수정은 불가능하다. 이 자료구조에서 데이터 공유가 어떻게 적용되고 있는지 그림으로 살펴보자.
그림처럼 각각 [a, b, c], [d, e, f]의 원소를 담고 있는 두 개의 단일 연결 리스트가 있다고 가정해보자.
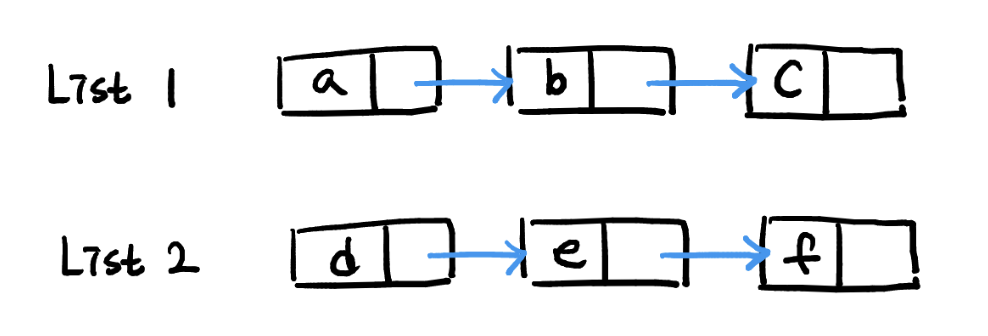
list1.addAll(list2)처럼 list1에 list2의 모든 원소를 추가한 list3을 만드는 상황을 가정해보자. 데이터 공유를 사용하지 않을 경우, list1과 list2의 모든 원소를 복사함으로써 총 6번의 복사가 필요하다.
- 모든 데이터를 복사할 경우 : O(n + m) for traversal of lists and O(1) each for adding (n + m – 1) connections.
데이터 공유를 사용하면 이 작업을 더 효율적으로 처리할 수 있다. 두 리스트의 사이즈가 N < M일 때, 크기가 N인 리스트의 데이터를 복사한다. 복사한 리스트의 마지막 요소를 크기가 M인 리스트에 연결한다.

새로 만들어진 list3의 데이터 일부는 list2의 데이터를 공유받고 있다. 데이터 공유를 활용하니 복사 횟수는 3번으로 줄어들고, 원본 데이터인 list1과 list2는 메모리 상에서 그대로 유지되고 있다.
- 데이터 공유를 사용할 경우 : O(m) for traversal and O(1) for each one of the (m) connections.
단일 연결 리스트 구현하기
이제 코드로 직접 구현해보자. 여기서 구현할 연결 리스트는 맨 앞에 원소를 추가하거나 삭제하는 연산의 경우 아주 짧은 상수 시간에 처리가 가능하다. 코틀린의 불변 리스트와 달리 어떤 복사도 일어나지 않기 때문이다. 데이터 공유를 적절히 사용하면 전부는 아니지만 일부 연산에서 좋은 성능을 얻을 수 있다.
재귀적인 리스트 구조의 등장인물
- head : 위에서 소개한 구조를 만들기 위해서는 원소 사이 연결을 가능하게 하는 머리가 필요하다. head는 리스트의 첫 번째 원소가 될 것이다.
- tail : 리스트의 나머지 부분
- Nil : 재귀 정의를 마무리하기 위한 종료 조건이 필요하다. Nil은 종료 조건으로 사용될 빈 리스트다.
이 세 가지를 실제 구현으로 옮겨보자.
open class List<T>
// 빈 리스트를 표현하는 클래스
object Nil : List<Nothing>()
// 비어있지 않은 Head와 Tail을 표현하는 클래스
class Cons<T>(private val head: T, private val tail: List<T>) : List<T>()누구나 리스트를 확장할 수 있도록, 그리고 구현 세부 사항인 Nil과 Cons를 숨기기 위해 sealed 클래스(클래스를 묶은 클래스)를 사용해서 List를 추상 클래스로 만든다.
sealed class List<T> {
internal object Nil : List<Nothing>()
internal class Cons<T>(private val head: T, private val tail: List<T>) : List<T>()
}List를 기반으로 단일 연결 리스트를 구현하는 코드다.
sealed class List<A> {
abstract fun isEmpty(): Boolean
private object Nil: List<Nothing>() {
override fun isEmpty() = true
override fun toString(): String = "[NIL]"
}
private class Cons<A>(internal val head: A, internal val tail: List<A>) : List<A>() {
override fun isEmpty() = false
override fun toString(): String = "[${toString("", this)}NIL]"
// 4장에서 배운 공재귀를 활용
private tailrec fun toString(acc: String, list: List<A>): String = when (list) {
Nil -> acc
is Cons -> toString("$acc${list.head}, ", list.tail)
}
}
companion object {
operator fun <A> invoke(vararg az: A): List<A> =
az.foldRight(Nil as List<A>) { a: A, list: List<A> -> Cons(a, list) }
}
}Cons 클래스는 머리 A와 꼬리 List<A>를 인자로 받는다.
operator 키워드와 invoke 함수를 함께 쓰면 클래스 이름() 형식으로 더 간단하게 호출이 가능하다.
// List 사용 방법
val list = List.invoke(1, 2, 3)
val list2 = List(1, 2, 3) // invoke()가 호출된다.5.5~5.6 리스트 연산 구현하기
연습문제가 꽤 많아서 그중 몇 가지만 정리한다. 모든 연산 메서드가 구현된 코드는 여기서 확인 가능.
1. 원소 삽입
리스트의 가장 끝에는 Nil이 있어야 하기 때문에, 새로운 원소 삽입은 리스트의 앞쪽에서 가능하다. 이때 새로 생성하는 Cons 객체의 tail로 자기 자신을 넘기고 있다. 이렇게 데이터 공유를 사용하기 때문에 삽입 연산이 빠르게 완료된다.
fun cons(a: A): List<A> = Cons(a, this)리스트를 하나 만들어서 원소를 삽입해보자.
fun main() {
val list = List(1, 2)
val list2 = list.cons(3).cons(4)
println(list) // [1, 2, NIL]
println(list2) // [4, 3, 1, 2, NIL]
}2. Head를 새로운 값으로 바꾸기
빈 리스트일 경우 값을 변경할 수 없으므로 예외를 던져야 한다.
fun setHead(a: A): List<A> = when (this) {
is Nil -> throw IllegalStateException("빈 리스트의 첫 번째 원소를 바꿀 수는 없습니다")
is Cons -> tail.cons(a)
}fun main() {
val list = List(1, 2)
val list2 = list.setHead(3)
println(list) // [1, 2, NIL]
println(list2) // [3, 2, NIL]
}3. 원소 삭제
n을 1씩 감소시키면서 재귀 함수가 한 번 호출될 때마다 head를 하나씩 떼어내고 있다. n이 0에 도달하고 나면 최종적으로 n개의 요소가 삭제된 리스트가 반환된다.
fun drop(n: Int): List<T> = drop(this, n)
tailrec fun <A> drop(list: List<A>, n: Int): List<A> = when (list) {
Nil -> list
is Cons -> if (n <= 0) list else drop(list.tail, n - 1)
}
fun dropWhile(p: (T) -> Boolean): List<T> = dropWhile(this, p)
tailrec fun <A> dropWhile(list: List<A>, p: (A) -> Boolean): List<A> = when (list) {
Nil -> list
is Cons -> if (p(list.head)) dropWhile(list.tail, p) else list
}fun main() {
val list = List(1, 2, 3, 4, 5)
val list2 = list.drop(2)
val list3 = list.dropWhile { it < 3 }
println(list) // [1, 2, 3, 4, 5, NIL]
println(list2) // [3, 4, 5, NIL]
println(list3) // [3, 4, 5, NIL]
}References
- www.baeldung.com/kotlin-immutable-collections
- https://medium.com/happyprogrammer-in-jeju/%ED%81%B4%EB%A1%9C%EC%A0%80%EB%9D%BC%EB%8A%94-%ED%9B%8C%EB%A5%AD%ED%95%9C-%EB%8F%84%EA%B5%AC%EC%99%80-%EC%98%81%EC%86%8D-%EB%B6%88%EB%B3%80-%EC%9E%90%EB%A3%8C-%EA%B5%AC%EC%A1%B0-4409d00f680b
- https://en.wikipedia.org/wiki/Persistent_data_structure
'if (study) > Java & Kotlin' 카테고리의 다른 글
| 코틀린을 다루는 기술 6장 정리 - 선택적 데이터 처리하기 (0) | 2020.07.24 |
|---|---|
| 코틀린을 다루는 기술 4장 정리 - 재귀, 공재귀, 메모화 (0) | 2020.07.17 |
| 코틀린을 다루는 기술 3장 정리 - 함수로 프로그래밍하기 (2) | 2020.07.05 |